
Ollama - faire tourner localement des modèles I.A.
Si vous souhaitez utiliser des LLMs (des I.A. conversationnelles), vous avez deux possibilités : les utiliser en ligne ou les installer sur votre ordinateur. Le deuxième choix peut paraître intimidant pour le non initié mais Ollama est là pour simplifier au maximum le côté technique. Si vous êtes sous Linux ou WSL2, vous n'avez qu'une seule commande à copier/coller dans votre Terminal :
curl -fsSL https://ollama.com/install.sh | shUne fois installé, la commande ci-dessous va télécharger et lancer le modèle choisi (ici Phi-2 de Microsoft Research) :
ollama run phiVous avez le choix parmi 81 modèles (actuellement) dont Gemma, Llama2, Mistral, etc.
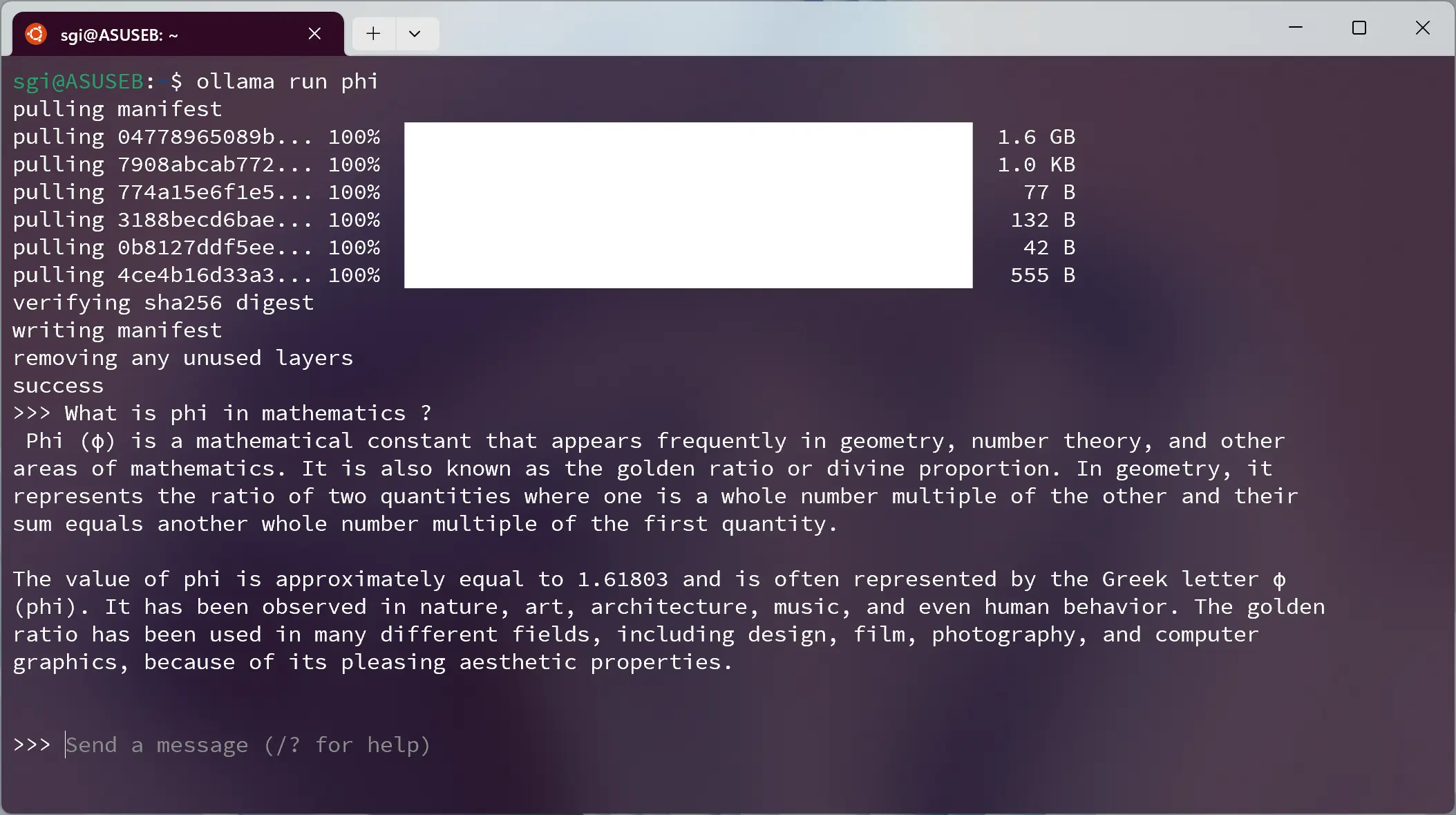
Pour sortir de l'invite de commande, c'est simple il sufit de faire Ctrl + D. Si vous installez
plusieurs modèles, vous pouvez les lister via la commande ollama list et supprimer un modèle se fait via
la commande ollama rm phi (ou "phi" est le nom du modèle). Il faut savoir qu'Ollama, pour fonctionner,
fait tourner un serveur ollama serve en tâche de fond sous votre localhost http://127.0.0.1:11434 (en copiant/collant
cette adresse, vous devriez voir les termes "ollama is running"). Pour arrêter le serveur, il faut taper la commande
sudo service ollama stop. Et si vous devez redémarrer le serveur, la commande est sudo service ollama start.
En plus d'être simple à prendre en main, Ollama est disponible sur Linux, Windows et macOS. Il peut être également intégré à tout un tas d'autres applications (terminaux, base de données, applications, etc.). N'hésitez pas à jeter un oeil sur la doc via la page Github du projet.
Ce que vous devez garder en mémoire, c'est que pour faire tourner un modèle localement, il faut certaines ressources. Pour des modèles de 3 à 7B, 8Gb de Ram sont nécessaires. Pour des modèles de 13B, 16Gb de Ram sont nécessaires. Pour des modèles plus imposants, la quantité de Ram devra encore être plus importante. Il est également recommandé d'avoir une bonne (voir très bonne) carte graphique. Si votre ordinateur a du mal à digérer certains modèles que vous souhaitez tester, il y a une solution et elle s'appelle Google Colab. C'est un service gratuit (dans une certaine mesure) accessible via votre navigateur et permettant d'écrire et d'exécuter du code Python sur les serveurs de Google. De plus, et c'est là que ça devient intéressant, il est possible de bénéficier d'un GPU (Tesla T4 avec 16Gb de GDDR6) gratuitement.
Pour faire simple, il suffit d'installer Ollama et le modèle choisi sur un Colab de Google. Alors comment faire ? Rendez vous sur le site
colab.research.google.com et connectez vous avec votre
compte Google. Voyez un Colab comme un bloc-notes dans lequel vous pouvez exécuter (en cliquant sur le petit bouton play à
gauche de la commande) du code comme susmentionné.
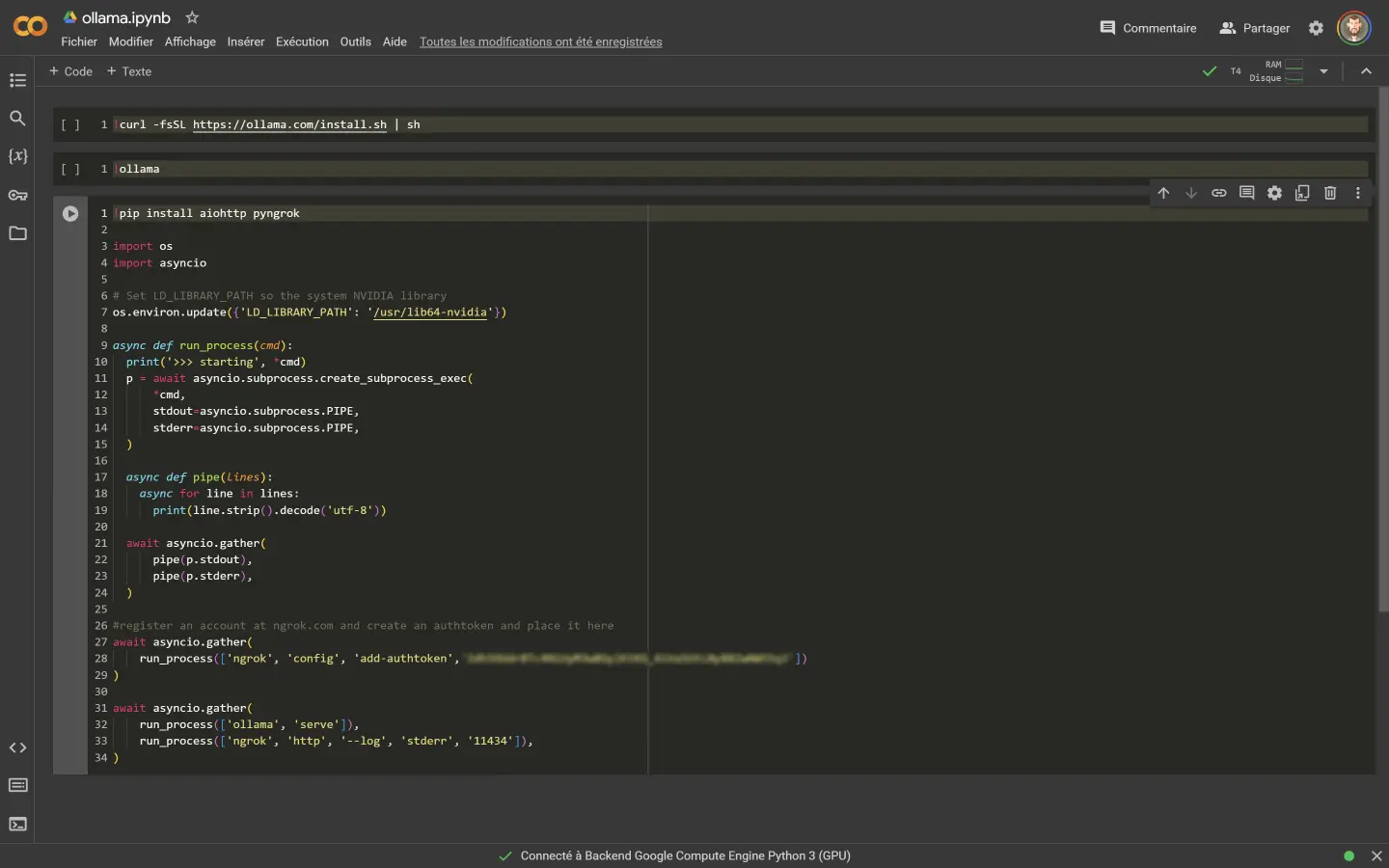
La première commande à entrée est celle-ci et permet d'installer ollama sur votre Colab :
!curl -fsSL https://ollama.com/install.sh | sh
Elle est préfixée par un ! qui veut dire qu'on utilise une commande Linux (derrière Colab se cache un environnement Linux). La
deuxième commande vérifie si ollama s'est bien installé :
!ollama
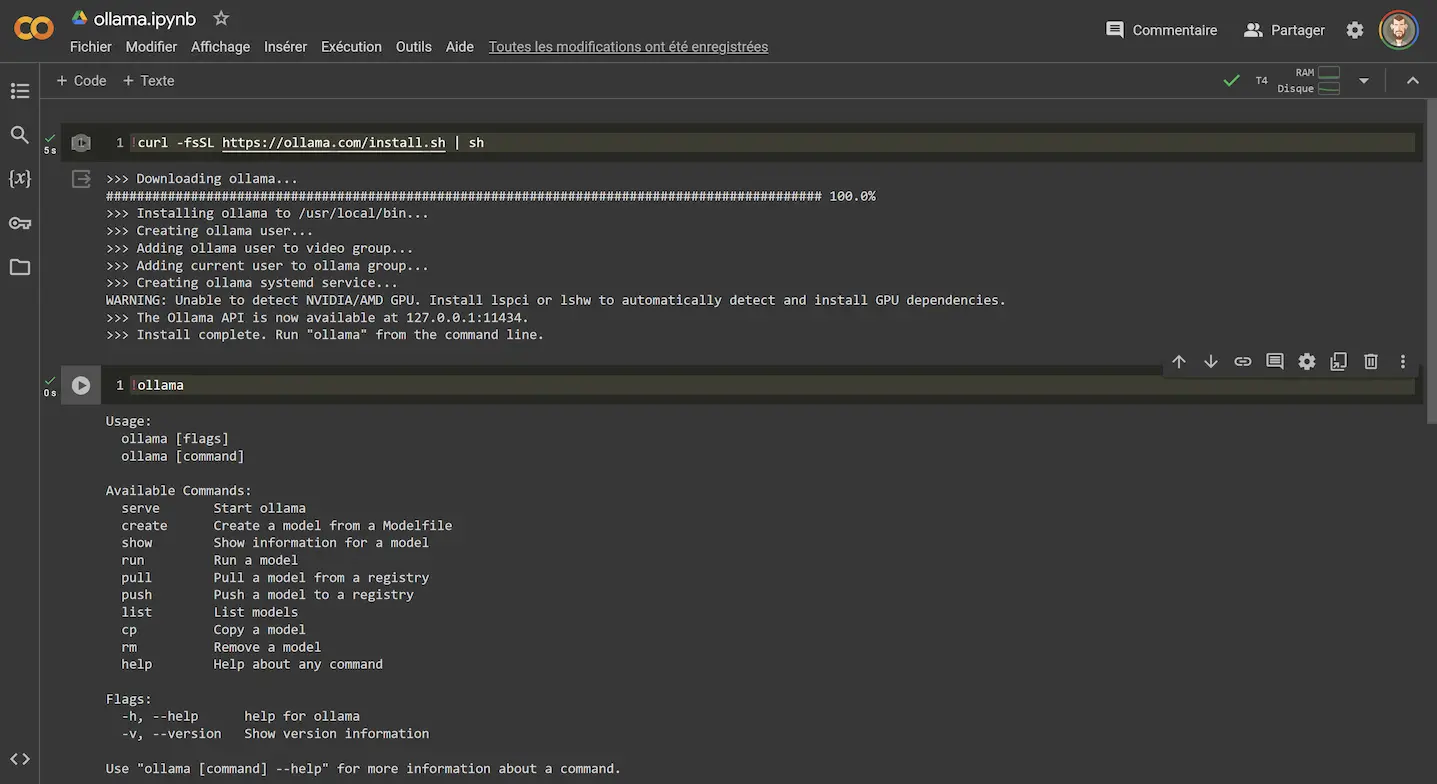
Les commandes suivantes (voir Figure 2) sont plus compliquées.
Pour simplifier, on fait en sorte que le code tourne sous le GPU du Colab. On fait appel au service
ngrok qui permet
de faire un "tunnel" virtuel entre le Colab et la machine locale (votre ordinateur). Et le tout est géré de façon asynchrone.
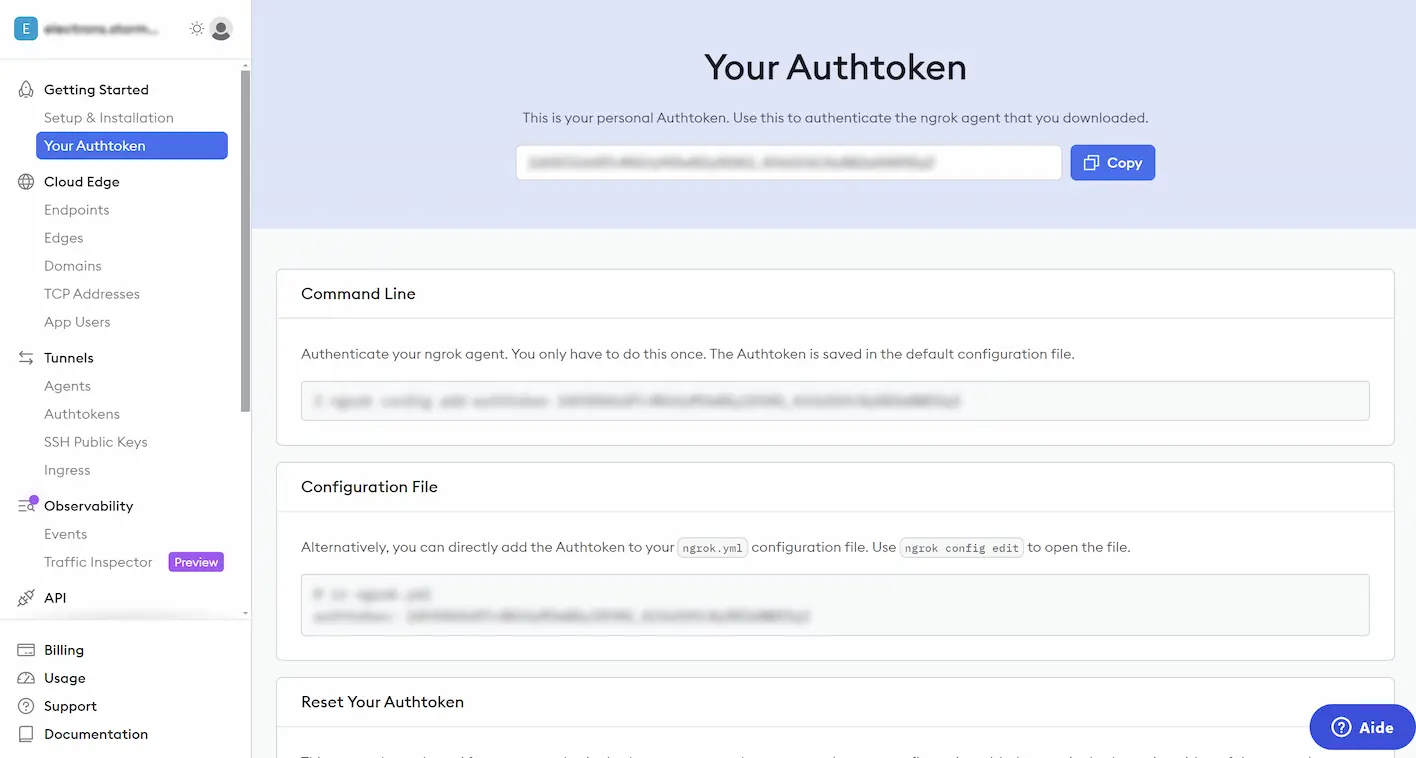
ngrok est un service gratuit et vous pouvez vous inscrire avec votre compte Google. Au niveau de la page
"Your Authtoken" de ngrok copiez l'Authtoken et collez-le dans le code au niveau de la ligne :
run_process(['ngrok', 'config', 'add-authtoken','ici votre Authtoken'])
Avant de lancer ces commandes, il faut "Modifier le type d'exécution" pour activer le GPU T4. Cela ce fait en cliquant en haut à droite, juste en dessous de l'avatar de votre compte.
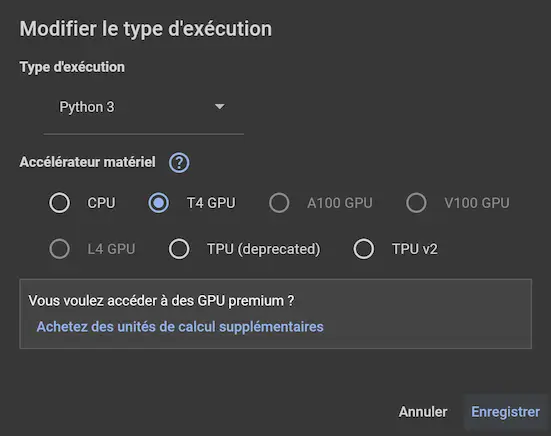
Une fois toutes les commandes lancées, vous devez repérer ceci msg="started tunnel" obj=tunnels name=command_line et copier l'URL contenant le terme "ngrok". Au niveau de votre installation locale d'Ollama, tapez export OLLAMA_HOST=https://ici l'adresse web copiée/ (cela fait le lien avec Google Colab via ngrok) puis la commande ollama run avec le nom du modèle choisi. Vous avez maintenant la possibilité de lancer des modèles plus gourmants en ressources. Par contre, il ne faut pas oublier que lors de la déconnexion de Google Colab, les modèles installés seront supprimés. Bon à noter également, c'est que le Colab est enregistré dans votre Google Drive. Dernière chose, si vous souhaitez réutiliser Ollama de façon locale, il faut taper la commande export OLLAMA_HOST=http://127.0.0.1:11434 (au niveau de votre installation locale).
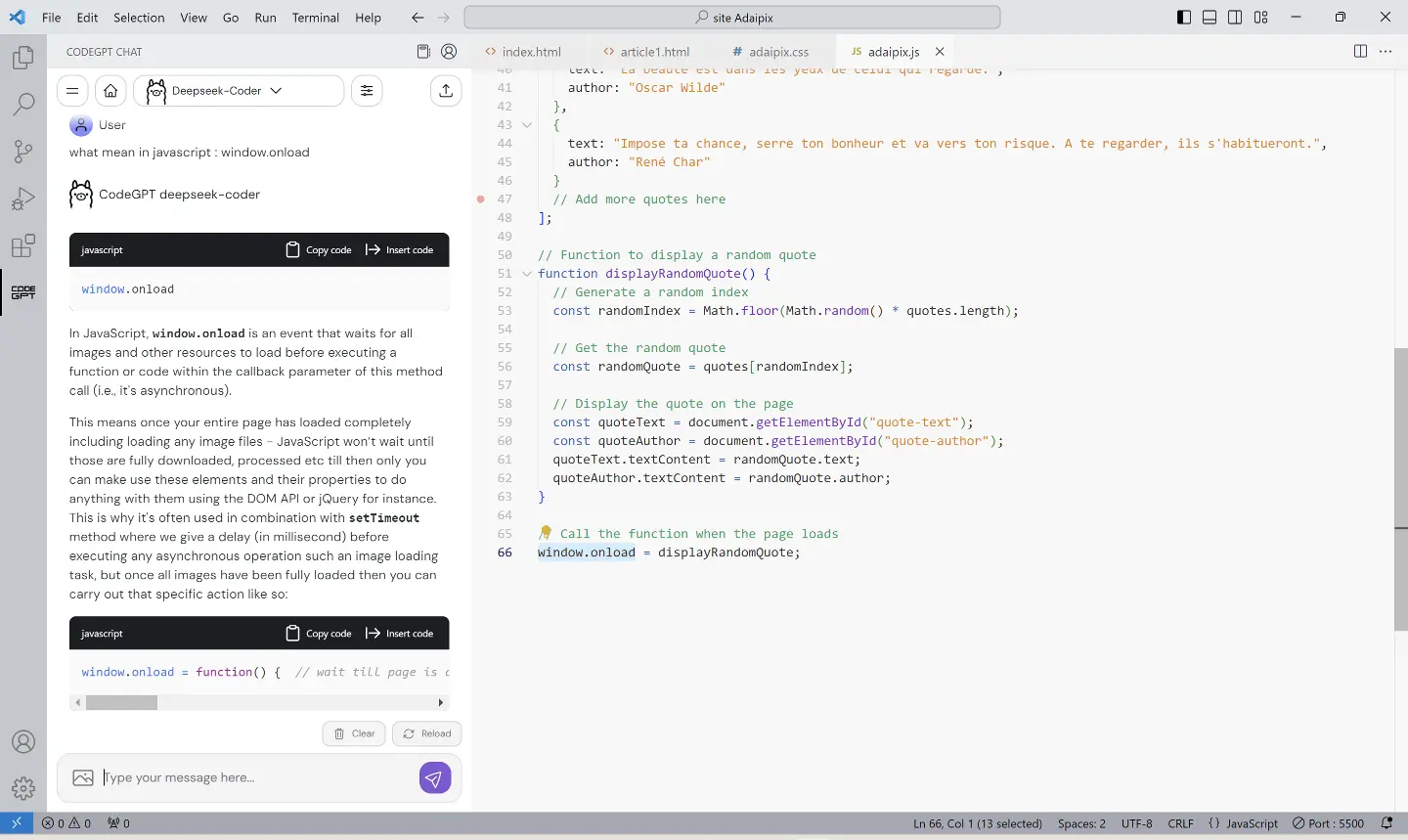
Pour conclure cet article, voici un exemple d'intégration d'Ollama dans une application. Si vous codez, vous connaissez certainement Visual Studio Code l'éditeur de code de Microsoft. Il est gratuit et disponible sur Windows, Linux, macOS et même accessible via un simple navigateur. Ce qui fait sa force est sans nul doute les nombreuses extensions qu'on peut lui adjoindre. Justement une de ces extensions est CodeGPT et permet de faire la liaison avec votre installation locale d'Ollama. Ce qui permet d'avoir accès à l'I.A. directement dans Visual Studio Code et de vous aider dans l'édition du code sur lequel vous travaillez. Pour installer cette extension, il suffit de cliquer sur l'icône "Extensions" ou faire Ctrl + Maj + X. Tapez dans la zone de recherche en haut à gauche "CodeGPT" et cliquez sur "Install". Vérifiez que l'extension est édité par codegpt.co. Au niveau de l'extension, en haut, cliquez sur "Select A Model" puis "Providers" et choisissez "Ollama". Ensuite, cliquez sur "Type the model name" et choisissez le modèle que vous souhaitez (il faut l'avoir précédemment installé via Ollama). Voilà, à vous de tester tout cela !
En résumé :
Ollama permet d'installer localement et facilement 81 modèles d'I.A. conversationnelles. Disponible sur Linux, Windows et macOS. C'est gratuit et open source. On peut l'interfacer avec Google Colab et d'autres applications.
Liens :
Run any AI model remotely for free on google colab - Tech with Marco.